-
1. Getting Started
- 1.1 About Version Control
- 1.2 A Short History of Git
- 1.3 What is Git?
- 1.4 The Command Line
- 1.5 Installing Git
- 1.6 First-Time Git Setup
- 1.7 Getting Help
- 1.8 Summary
-
2. Git Basics
- 2.1 Getting a Git Repository
- 2.2 Recording Changes to the Repository
- 2.3 Viewing the Commit History
- 2.4 Undoing Things
- 2.5 Working with Remotes
- 2.6 Tagging
- 2.7 Git Aliases
- 2.8 Summary
-
3. Git Branching
- 3.1 Branches in a Nutshell
- 3.2 Basic Branching and Merging
- 3.3 Branch Management
- 3.4 Branching Workflows
- 3.5 Remote Branches
- 3.6 Rebasing
- 3.7 Summary
-
4. Git on the Server
- 4.1 The Protocols
- 4.2 Getting Git on a Server
- 4.3 Generating Your SSH Public Key
- 4.4 Setting Up the Server
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Third Party Hosted Options
- 4.10 Summary
-
5. Distributed Git
- 5.1 Distributed Workflows
- 5.2 Contributing to a Project
- 5.3 Maintaining a Project
- 5.4 Summary
-
6. GitHub
-
7. Git Tools
- 7.1 Revision Selection
- 7.2 Interactive Staging
- 7.3 Stashing and Cleaning
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Rewriting History
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugging with Git
- 7.11 Submodules
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Summary
-
8. Customizing Git
- 8.1 Git Configuration
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Summary
-
9. Git and Other Systems
- 9.1 Git as a Client
- 9.2 Migrating to Git
- 9.3 Summary
-
10. Git Internals
- 10.1 Plumbing and Porcelain
- 10.2 Git Objects
- 10.3 Git References
- 10.4 Packfiles
- 10.5 The Refspec
- 10.6 Transfer Protocols
- 10.7 Maintenance and Data Recovery
- 10.8 Environment Variables
- 10.9 Summary
-
A1. Appendix A: Git in Other Environments
- A1.1 Graphical Interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Visual Studio Code
- A1.4 Git in IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine
- A1.5 Git in Sublime Text
- A1.6 Git in Bash
- A1.7 Git in Zsh
- A1.8 Git in PowerShell
- A1.9 Summary
-
A2. Appendix B: Embedding Git in your Applications
- A2.1 Command-line Git
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. Appendix C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
3.1 Git Branching - Branches in a Nutshell
Nearly every VCS has some form of branching support. Branching means you diverge from the main line of development and continue to do work without messing with that main line. In many VCS tools, this is a somewhat expensive process, often requiring you to create a new copy of your source code directory, which can take a long time for large projects.
Some people refer to Git’s branching model as its “killer feature,” and it certainly sets Git apart in the VCS community. Why is it so special? The way Git branches is incredibly lightweight, making branching operations nearly instantaneous, and switching back and forth between branches generally just as fast. Unlike many other VCSs, Git encourages workflows that branch and merge often, even multiple times in a day. Understanding and mastering this feature gives you a powerful and unique tool and can entirely change the way that you develop.
Branches in a Nutshell
To really understand the way Git does branching, we need to take a step back and examine how Git stores its data.
As you may remember from What is Git?, Git doesn’t store data as a series of changesets or differences, but instead as a series of snapshots.
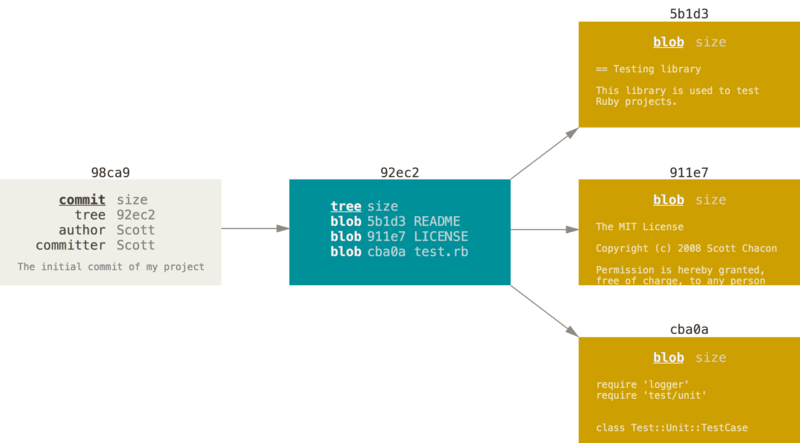
When you make a commit, Git stores a commit object that contains a pointer to the snapshot of the content you staged. This object also contains the author’s name and email address, the message that you typed, and pointers to the commit or commits that directly came before this commit (its parent or parents): zero parents for the initial commit, one parent for a normal commit, and multiple parents for a commit that results from a merge of two or more branches.
To visualize this, let’s assume that you have a directory containing three files, and you stage them all and commit. Staging the files computes a checksum for each one (the SHA-1 hash we mentioned in What is Git?), stores that version of the file in the Git repository (Git refers to them as blobs), and adds that checksum to the staging area:
$ git add README test.rb LICENSE
$ git commit -m 'Initial commit'When you create the commit by running git commit, Git checksums each subdirectory (in this case, just the root project directory) and stores them as a tree object in the Git repository.
Git then creates a commit object that has the metadata and a pointer to the root project tree so it can re-create that snapshot when needed.
Your Git repository now contains five objects: three blobs (each representing the contents of one of the three files), one tree that lists the contents of the directory and specifies which file names are stored as which blobs, and one commit with the pointer to that root tree and all the commit metadata.
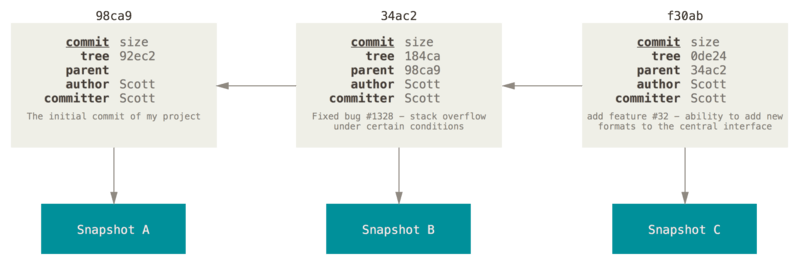
If you make some changes and commit again, the next commit stores a pointer to the commit that came immediately before it.
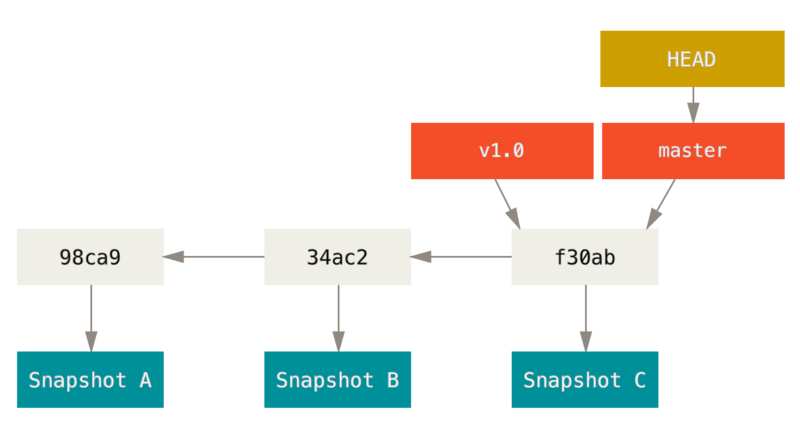
A branch in Git is simply a lightweight movable pointer to one of these commits.
The default branch name in Git is master.
As you start making commits, you’re given a master branch that points to the last commit you made.
Every time you commit, the master branch pointer moves forward automatically.
|
Note
|
The “master” branch in Git is not a special branch.
It is exactly like any other branch.
The only reason nearly every repository has one is that the |
Creating a New Branch
What happens when you create a new branch?
Well, doing so creates a new pointer for you to move around.
Let’s say you want to create a new branch called testing.
You do this with the git branch command:
$ git branch testingThis creates a new pointer to the same commit you’re currently on.
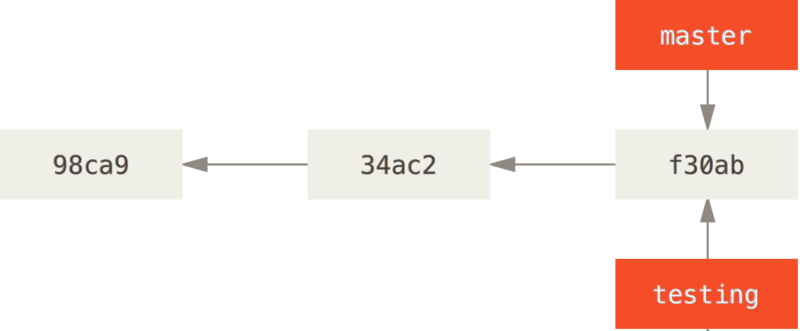
How does Git know what branch you’re currently on?
It keeps a special pointer called HEAD.
Note that this is a lot different than the concept of HEAD in other VCSs you may be used to, such as Subversion or CVS.
In Git, this is a pointer to the local branch you’re currently on.
In this case, you’re still on master.
The git branch command only created a new branch — it didn’t switch to that branch.
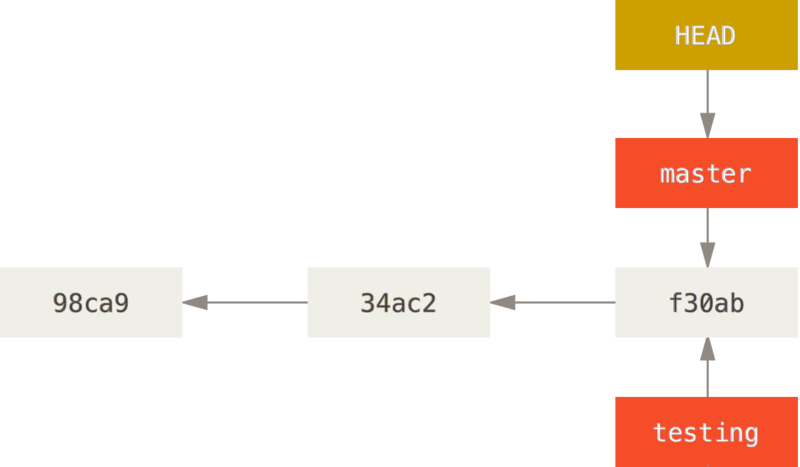
You can easily see this by running a simple git log command that shows you where the branch pointers are pointing.
This option is called --decorate.
$ git log --oneline --decorate
f30ab (HEAD -> master, testing) Add feature #32 - ability to add new formats to the central interface
34ac2 Fix bug #1328 - stack overflow under certain conditions
98ca9 Initial commitYou can see the master and testing branches that are right there next to the f30ab commit.
Switching Branches
To switch to an existing branch, you run the git checkout command.
Let’s switch to the new testing branch:
$ git checkout testingThis moves HEAD to point to the testing branch.
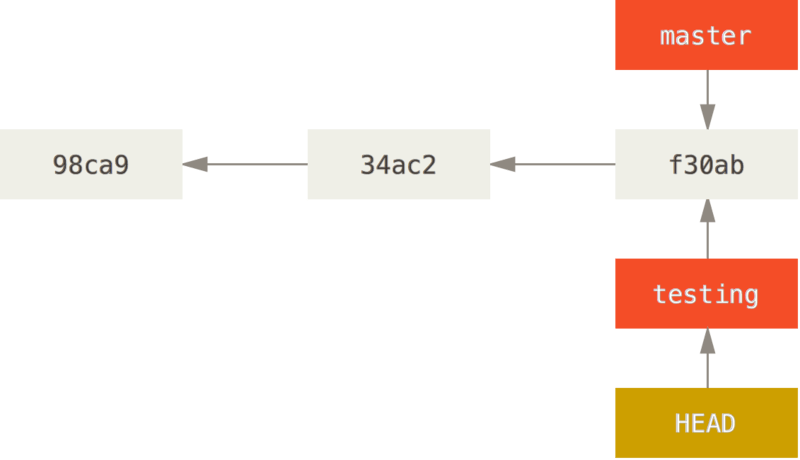
What is the significance of that? Well, let’s do another commit:
$ vim test.rb
$ git commit -a -m 'Make a change'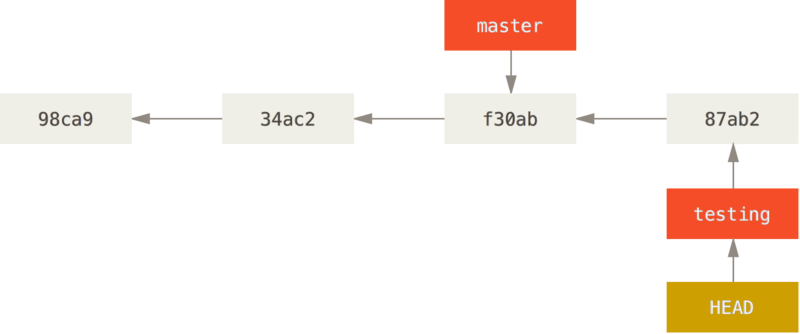
This is interesting, because now your testing branch has moved forward, but your master branch still points to the commit you were on when you ran git checkout to switch branches.
Let’s switch back to the master branch:
$ git checkout master|
Note
|
git log doesn’t show all the branches all the timeIf you were to run The branch hasn’t disappeared; Git just doesn’t know that you’re interested in that branch and it is trying to show you what it thinks you’re interested in.
In other words, by default, To show commit history for the desired branch you have to explicitly specify it: |
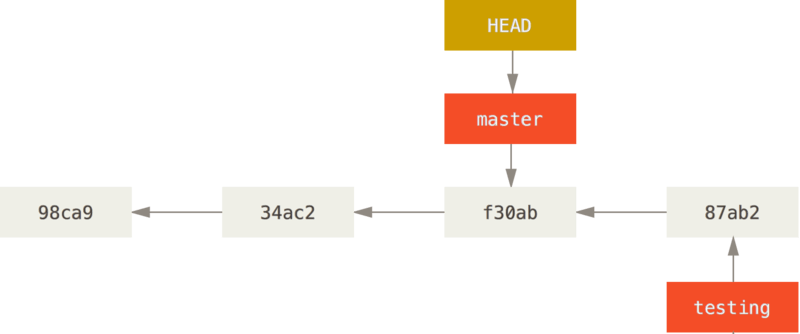
That command did two things.
It moved the HEAD pointer back to point to the master branch, and it reverted the files in your working directory back to the snapshot that master points to.
This also means the changes you make from this point forward will diverge from an older version of the project.
It essentially rewinds the work you’ve done in your testing branch so you can go in a different direction.
|
Note
|
Switching branches changes files in your working directory
It’s important to note that when you switch branches in Git, files in your working directory will change. If you switch to an older branch, your working directory will be reverted to look like it did the last time you committed on that branch. If Git cannot do it cleanly, it will not let you switch at all. |
Let’s make a few changes and commit again:
$ vim test.rb
$ git commit -a -m 'Make other changes'Now your project history has diverged (see Divergent history).
You created and switched to a branch, did some work on it, and then switched back to your main branch and did other work.
Both of those changes are isolated in separate branches: you can switch back and forth between the branches and merge them together when you’re ready.
And you did all that with simple branch, checkout, and commit commands.
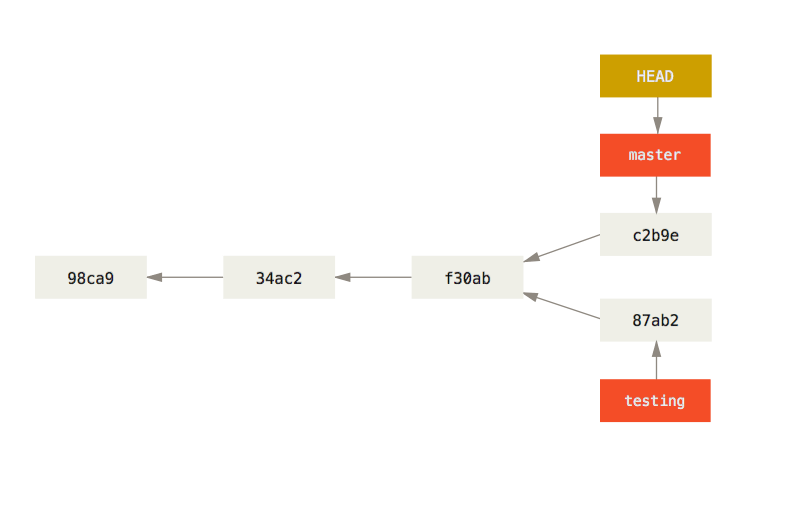
You can also see this easily with the git log command.
If you run git log --oneline --decorate --graph --all it will print out the history of your commits, showing where your branch pointers are and how your history has diverged.
$ git log --oneline --decorate --graph --all
* c2b9e (HEAD, master) Make other changes
| * 87ab2 (testing) Make a change
|/
* f30ab Add feature #32 - ability to add new formats to the central interface
* 34ac2 Fix bug #1328 - stack overflow under certain conditions
* 98ca9 Initial commit of my projectBecause a branch in Git is actually a simple file that contains the 40 character SHA-1 checksum of the commit it points to, branches are cheap to create and destroy. Creating a new branch is as quick and simple as writing 41 bytes to a file (40 characters and a newline).
This is in sharp contrast to the way most older VCS tools branch, which involves copying all of the project’s files into a second directory. This can take several seconds or even minutes, depending on the size of the project, whereas in Git the process is always instantaneous. Also, because we’re recording the parents when we commit, finding a proper merge base for merging is automatically done for us and is generally very easy to do. These features help encourage developers to create and use branches often.
Let’s see why you should do so.
|
Note
|
Creating a new branch and switching to it at the same time
It’s typical to create a new branch and want to switch to that new branch at the same time — this can be done in one operation with |
|
Note
|
From Git version 2.23 onwards you can use
|