Extending Kubernetes
Kubernetes is highly configurable and extensible. As a result, there is rarely a need to fork or submit patches to the Kubernetes project code.
This guide describes the options for customizing a Kubernetes cluster. It is aimed at cluster operators who want to understand how to adapt their Kubernetes cluster to the needs of their work environment. Developers who are prospective Platform Developers or Kubernetes Project Contributors will also find it useful as an introduction to what extension points and patterns exist, and their trade-offs and limitations.
Overview
Customization approaches can be broadly divided into configuration, which only involves changing flags, local configuration files, or API resources; and extensions, which involve running additional programs or services. This document is primarily about extensions.
Configuration
Configuration files and flags are documented in the Reference section of the online documentation, under each binary:
Flags and configuration files may not always be changeable in a hosted Kubernetes service or a distribution with managed installation. When they are changeable, they are usually only changeable by the cluster administrator. Also, they are subject to change in future Kubernetes versions, and setting them may require restarting processes. For those reasons, they should be used only when there are no other options.
Built-in Policy APIs, such as ResourceQuota, PodSecurityPolicies, NetworkPolicy and Role-based Access Control (RBAC), are built-in Kubernetes APIs. APIs are typically used with hosted Kubernetes services and with managed Kubernetes installations. They are declarative and use the same conventions as other Kubernetes resources like pods, so new cluster configuration can be repeatable and be managed the same way as applications. And, where they are stable, they enjoy a defined support policy like other Kubernetes APIs. For these reasons, they are preferred over configuration files and flags where suitable.
Extensions
Extensions are software components that extend and deeply integrate with Kubernetes. They adapt it to support new types and new kinds of hardware.
Many cluster administrators use a hosted or distribution instance of Kubernetes. These clusters come with extensions pre-installed. As a result, most Kubernetes users will not need to install extensions and even fewer users will need to author new ones.
Extension Patterns
Kubernetes is designed to be automated by writing client programs. Any program that reads and/or writes to the Kubernetes API can provide useful automation. Automation can run on the cluster or off it. By following the guidance in this doc you can write highly available and robust automation. Automation generally works with any Kubernetes cluster, including hosted clusters and managed installations.
There is a specific pattern for writing client programs that work well with
Kubernetes called the Controller pattern. Controllers typically read an
object's .spec, possibly do things, and then update the object's .status.
A controller is a client of Kubernetes. When Kubernetes is the client and calls out to a remote service, it is called a Webhook. The remote service is called a Webhook Backend. Like Controllers, Webhooks do add a point of failure.
In the webhook model, Kubernetes makes a network request to a remote service. In the Binary Plugin model, Kubernetes executes a binary (program). Binary plugins are used by the kubelet (e.g. Flex Volume Plugins and Network Plugins) and by kubectl.
Below is a diagram showing how the extension points interact with the Kubernetes control plane.
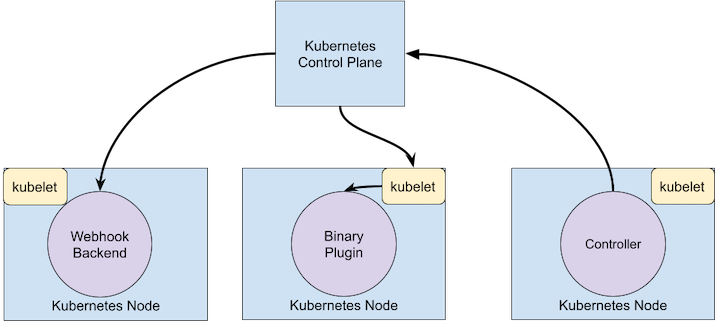
Extension Points
This diagram shows the extension points in a Kubernetes system.
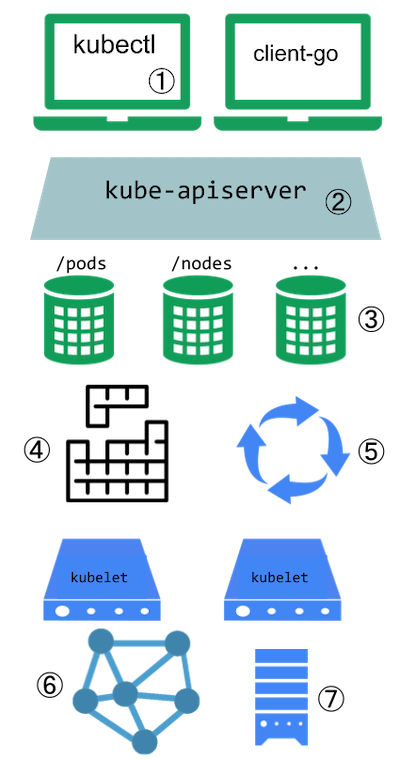
- Users often interact with the Kubernetes API using
kubectl. Kubectl plugins extend the kubectl binary. They only affect the individual user's local environment, and so cannot enforce site-wide policies. - The apiserver handles all requests. Several types of extension points in the apiserver allow authenticating requests, or blocking them based on their content, editing content, and handling deletion. These are described in the API Access Extensions section.
- The apiserver serves various kinds of resources. Built-in resource kinds, like
pods, are defined by the Kubernetes project and can't be changed. You can also add resources that you define, or that other projects have defined, called Custom Resources, as explained in the Custom Resources section. Custom Resources are often used with API Access Extensions. - The Kubernetes scheduler decides which nodes to place pods on. There are several ways to extend scheduling. These are described in the Scheduler Extensions section.
- Much of the behavior of Kubernetes is implemented by programs called Controllers which are clients of the API-Server. Controllers are often used in conjunction with Custom Resources.
- The kubelet runs on servers, and helps pods appear like virtual servers with their own IPs on the cluster network. Network Plugins allow for different implementations of pod networking.
- The kubelet also mounts and unmounts volumes for containers. New types of storage can be supported via Storage Plugins.
If you are unsure where to start, this flowchart can help. Note that some solutions may involve several types of extensions.
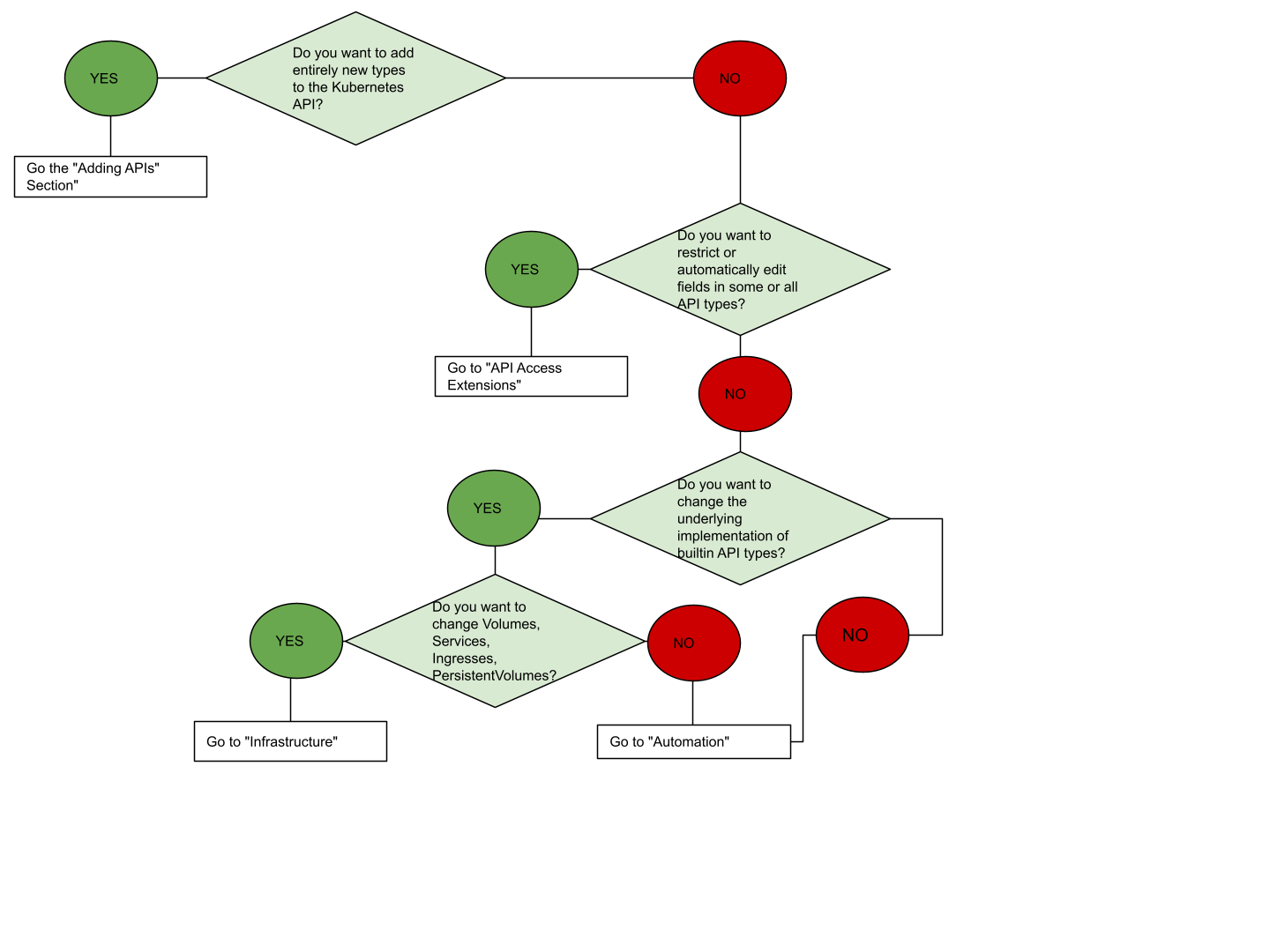
API Extensions
User-Defined Types
Consider adding a Custom Resource to Kubernetes if you want to define new controllers, application configuration objects or other declarative APIs, and to manage them using Kubernetes tools, such as kubectl.
Do not use a Custom Resource as data storage for application, user, or monitoring data.
For more about Custom Resources, see the Custom Resources concept guide.
Combining New APIs with Automation
The combination of a custom resource API and a control loop is called the Operator pattern. The Operator pattern is used to manage specific, usually stateful, applications. These custom APIs and control loops can also be used to control other resources, such as storage or policies.
Changing Built-in Resources
When you extend the Kubernetes API by adding custom resources, the added resources always fall into a new API Groups. You cannot replace or change existing API groups. Adding an API does not directly let you affect the behavior of existing APIs (e.g. Pods), but API Access Extensions do.
API Access Extensions
When a request reaches the Kubernetes API Server, it is first Authenticated, then Authorized, then subject to various types of Admission Control. See Controlling Access to the Kubernetes API for more on this flow.
Each of these steps offers extension points.
Kubernetes has several built-in authentication methods that it supports. It can also sit behind an authenticating proxy, and it can send a token from an Authorization header to a remote service for verification (a webhook). All of these methods are covered in the Authentication documentation.
Authentication
Authentication maps headers or certificates in all requests to a username for the client making the request.
Kubernetes provides several built-in authentication methods, and an Authentication webhook method if those don't meet your needs.
Authorization
Authorization determines whether specific users can read, write, and do other operations on API resources. It works at the level of whole resources -- it doesn't discriminate based on arbitrary object fields. If the built-in authorization options don't meet your needs, Authorization webhook allows calling out to user-provided code to make an authorization decision.
Dynamic Admission Control
After a request is authorized, if it is a write operation, it also goes through Admission Control steps. In addition to the built-in steps, there are several extensions:
- The Image Policy webhook restricts what images can be run in containers.
- To make arbitrary admission control decisions, a general Admission webhook can be used. Admission Webhooks can reject creations or updates.
Infrastructure Extensions
Storage Plugins
FlexVolume is deprecated since Kubernetes v1.23. The Out-of-tree CSI driver is the recommended way to write volume drivers in Kubernetes. See
Device plugins allow a node to discover new Node resources (in addition to the
builtin ones like cpu and memory) via a
Device Plugin. Different networking fabrics can be supported via node-level
Network Plugins. The scheduler is a special type of controller that watches pods, and assigns
pods to nodes. The default scheduler can be replaced entirely, while
continuing to use other Kubernetes components, or
multiple schedulers
can run at the same time. This is a significant undertaking, and almost all Kubernetes users find they
do not need to modify the scheduler. The scheduler also supports a
that permits a webhook backend (scheduler extension) to filter and prioritize
the nodes chosen for a pod.Device Plugins
Network Plugins
Scheduler Extensions
What's next